Video To Text
Were equations, pictures or diagrams not properly rendered, please refresh the page. If the problem persists, you can contact me.
To convert video files into text files, there are two steps to finish to achieve the goal.
- Convert videos into audio.
- Call the iFLYTEK API to achieve the conversion from audio to text.
MP4 To MP3
from moviepy import AudioFileClip
my=AudioFileClip("myvideo.mp4") # 你的视频地址
my.write_audiofile("my.mp3") # 设置生成的音频
MP3 To TXT
After converting the video into audio, we will then continue to complete the conversion of audio into text. Here, we will utilize the iFLYTEK API.
import base64
import hashlib
import hmac
import json
import os
import time
import re
import requests
from moviepy.editor import AudioFileClip
my=AudioFileClip("myvideo.mp4")
my.write_audiofile("my.mp3")
lfasr_host = 'http://raasr.xfyun.cn/api'
api_prepare = '/prepare'
api_upload = '/upload'
api_merge = '/merge'
api_get_progress = '/getProgress'
api_get_result = '/getResult'
file_piece_sice = 10485760
lfasr_type = 0
has_participle = 'false'
has_seperate = 'true'
max_alternatives = 0
suid = ''
class SliceIdGenerator:
"""slice id生成器"""
def __init__(self):
self.__ch = 'aaaaaaaaa`'
def getNextSliceId(self):
ch = self.__ch
j = len(ch) - 1
while j >= 0:
cj = ch[j]
if cj != 'z':
ch = ch[:j] + chr(ord(cj) + 1) + ch[j + 1:]
break
else:
ch = ch[:j] + 'a' + ch[j + 1:]
j = j - 1
self.__ch = ch
return self.__ch
class RequestApi(object):
def __init__(self, appid, secret_key, upload_file_path):
self.appid = appid
self.secret_key = secret_key
self.upload_file_path = upload_file_path
def gene_params(self, apiname, taskid=None, slice_id=None):
appid = self.appid
secret_key = self.secret_key
upload_file_path = self.upload_file_path
ts = str(int(time.time()))
m2 = hashlib.md5()
m2.update((appid + ts).encode('utf-8'))
md5 = m2.hexdigest()
md5 = bytes(md5, encoding='utf-8')
signa = hmac.new(secret_key.encode('utf-8'), md5, hashlib.sha1).digest()
signa = base64.b64encode(signa)
signa = str(signa, 'utf-8')
file_len = os.path.getsize(upload_file_path)
file_name = os.path.basename(upload_file_path)
param_dict = {}
if apiname == api_prepare:
slice_num = int(file_len / file_piece_sice) + (0 if (file_len % file_piece_sice == 0) else 1)
param_dict['app_id'] = appid
param_dict['signa'] = signa
param_dict['ts'] = ts
param_dict['file_len'] = str(file_len)
param_dict['file_name'] = file_name
param_dict['slice_num'] = str(slice_num)
elif apiname == api_upload:
param_dict['app_id'] = appid
param_dict['signa'] = signa
param_dict['ts'] = ts
param_dict['task_id'] = taskid
param_dict['slice_id'] = slice_id
elif apiname == api_merge:
param_dict['app_id'] = appid
param_dict['signa'] = signa
param_dict['ts'] = ts
param_dict['task_id'] = taskid
param_dict['file_name'] = file_name
elif apiname == api_get_progress or apiname == api_get_result:
param_dict['app_id'] = appid
param_dict['signa'] = signa
param_dict['ts'] = ts
param_dict['task_id'] = taskid
return param_dict
def gene_request(self, apiname, data, files=None, headers=None):
response = requests.post(lfasr_host + apiname, data=data, files=files, headers=headers)
result = json.loads(response.text)
if result["ok"] == 0:
if apiname=='/getResult':
results=re.findall(r"\"onebest\":\"(.+?)\",",result['data'])
print(results)
upload_file_path = self.upload_file_path
with open(str(upload_file_path)+".txt", "a", encoding='utf-8') as f:
for i in results:
f.write(i)
print("{} success:".format(apiname) + str(result))
return result
else:
print("{} error:".format(apiname) + str(result))
exit(0)
return result
def prepare_request(self):
return self.gene_request(apiname=api_prepare,
data=self.gene_params(api_prepare))
def upload_request(self, taskid, upload_file_path):
file_object = open(upload_file_path, 'rb')
try:
index = 1
sig = SliceIdGenerator()
while True:
content = file_object.read(file_piece_sice)
if not content or len(content) == 0:
break
files = {
"filename": self.gene_params(api_upload).get("slice_id"),
"content": content
}
response = self.gene_request(api_upload, data=self.gene_params(api_upload, taskid=taskid, slice_id=sig.getNextSliceId()), files=files)
if response.get('ok') != 0:
print('upload slice fail, response: ' + str(response))
return False
print('upload slice ' + str(index) + ' success')
index += 1
finally:
'file index:' + str(file_object.tell())
file_object.close()
return True
def merge_request(self, taskid):
return self.gene_request(api_merge, data=self.gene_params(api_merge, taskid=taskid))
def get_progress_request(self, taskid):
return self.gene_request(api_get_progress, data=self.gene_params(api_get_progress, taskid=taskid))
def get_result_request(self, taskid):
return self.gene_request(api_get_result, data=self.gene_params(api_get_result, taskid=taskid))
def all_api_request(self):
pre_result = self.prepare_request()
taskid = pre_result["data"]
self.upload_request(taskid=taskid, upload_file_path=self.upload_file_path)
self.merge_request(taskid=taskid)
while True:
progress = self.get_progress_request(taskid)
progress_dic = progress
if progress_dic['err_no'] != 0 and progress_dic['err_no'] != 26605:
print('task error: ' + progress_dic['failed'])
return
else:
data = progress_dic['data']
task_status = json.loads(data)
if task_status['status'] == 9:
print('task ' + taskid + ' finished')
break
print('The task ' + taskid + ' is in processing, task status: ' + str(data))
time.sleep(20)
self.get_result_request(taskid=taskid)
if __name__ == '__main__':
# 这里记得输入自己的id和key
api = RequestApi(appid="***", secret_key="***", upload_file_path=r"my.mp3")
api.all_api_request()
The acquisition of the iFLYTEK API and key for converting audio to text is shown in the figure as follows.
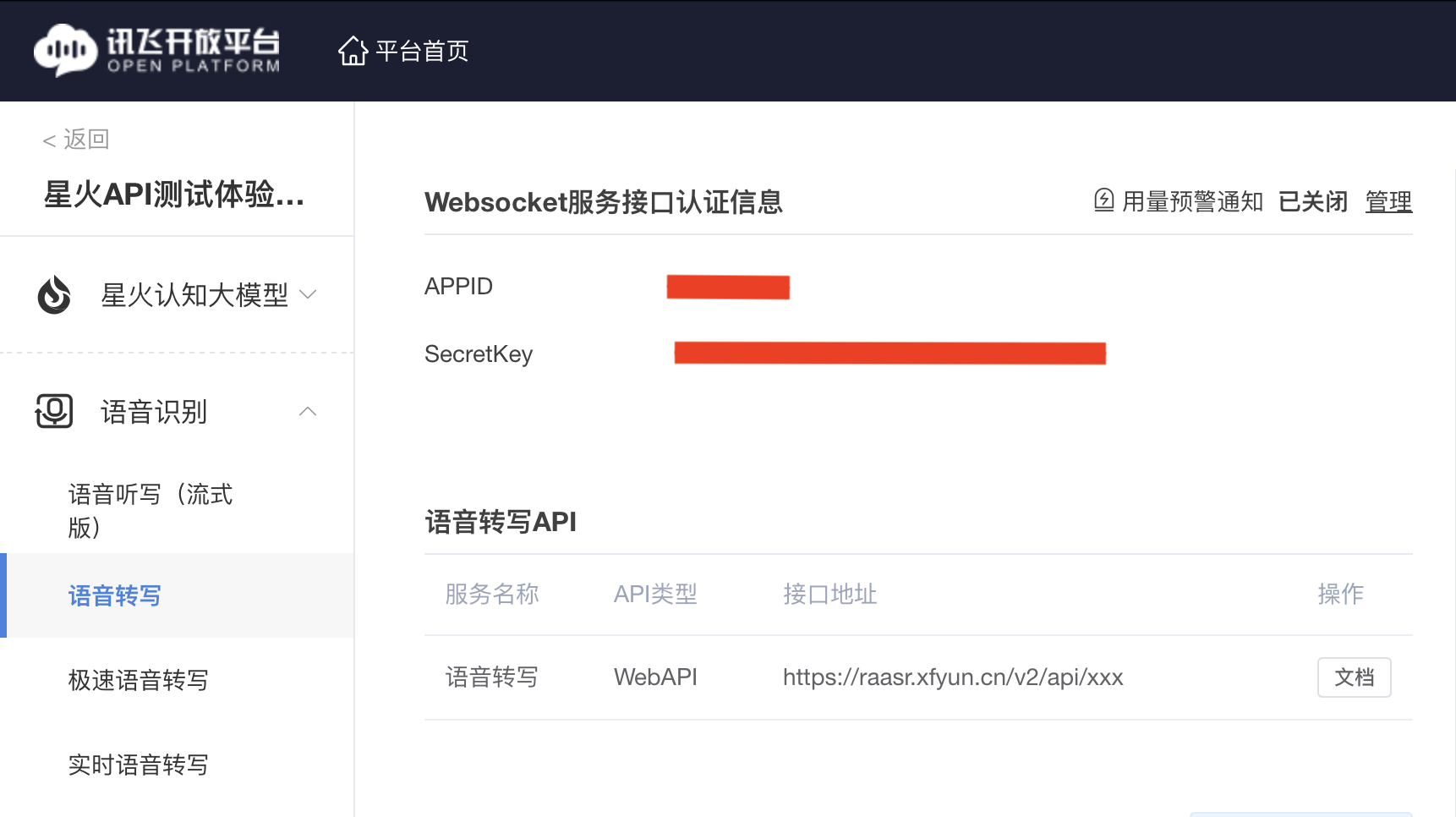
This article is forked from here.
Comments
Be the first one to comment on this page!