Natural Language Processing
自然语言处理是人工智能的一个子领域,旨在让机器像人类一样理解自然语言。
NLP 技术的力量可以追溯到 1950 年代的图灵测试,该测试用于确定机器是否可以被认为是智能的。
A computer would deserve to be called intelligent if it could deceive a human into believing that it was human. ————Alan Turing
What is NLP
自然语言处理 (NLP) 是计算机科学的一个领域,特别是人工智能 (AI) 的一个子集,专注于使计算机能够像人类一样理解文本和口语。
它需要开发算法和模型,使计算机能够理解、解释和生成书面和口头形式的人类语言。
机器中自然语言处理的任务分为两个子任务:
- 自然语言理解:不仅旨在处理语言的句法结构,而且还从中导出语义的技术属于此子任务——语音识别、命名实体识别、文本分类。
- 自然语言生成:从 NLU 派生的知识通过语言生成更进一步。例如 – 问答、文本生成(您在上面读过的 GPT 的诗)、语音生成(在虚拟助手中找到)。
现在,诸如语言翻译、搜索自动建议之类的NLP应用程序从名称来看可能看起来很简单,但它们是使用一些基本且简单的 NLP 技术的管道开发的。在继续讨论这些技术之前,让我们简要概述一下常用的两种主要类型的 NLP 算法
- 基于规则的系统:这些算法使用预定义的规则和模式来处理和理解语言。
- 基于机器学习的系统:这些算法使用统计和机器学习技术从数据中学习,并根据文本中的模式进行预测或分类。
上世纪 40 年代计算机被发明,用机器而非人力来处理信息成为可能。早在 1950 年代,自然语言处理就已经成为了计算机科学的一个研究领域。
不过一直到 1980 年代,NLP 系统是以一套复杂的人工订制规则为基础,计算机只是机械地执行这些规则,或者做一些诸如字符匹配,词频统计之类的简单计算。
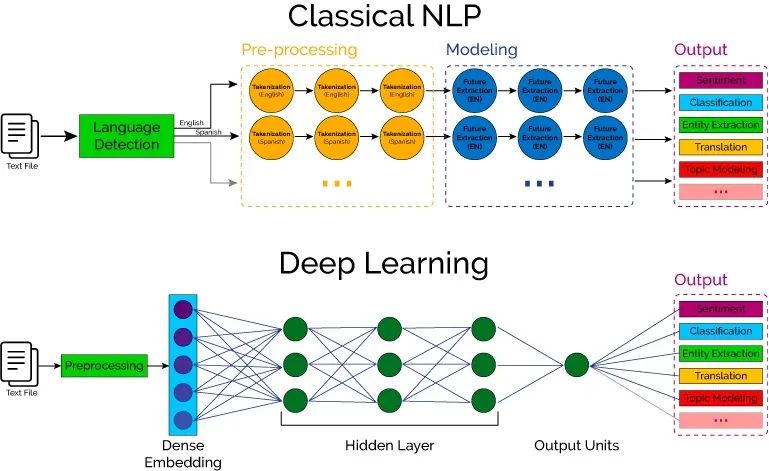
1980年代末期,机器学习的崛起为 NLP 引入了新的思路。刚性的文字处理人工规则日益被柔性的、以概率为基础的统计模型所替代。
近些年来,随着深度学习的发展,各类神经网络也被引入 NLP 领域,成为了解决问题的技术。
应当注意的是,自然语言处理(NLP)指以计算机为工具解决一系列现实中和自然语言相关的问题,机器学习、深度学习是解决这些问题的具体手段。
当我们关注 NLP 这一领域时要分清本末,要做的事情是本,做事的方式方法是末。如果神经网络能够解决我们的问题,我们当然应该采用,但并不是只要去解决问题,就一定要用神经网络。
NLP Tasks
NLP 要处理的问题纷繁复杂,而且每一个问题都要结合相应场景和具体需求才好讨论。
不过这些问题也有相当多的共性,基于这些共性,我们将千奇百怪的待解决 NLP 问题抽象为若干任务。
拼写提示、实体消歧、公指消解、自动摘要、阅读理解等等,都是常见的 NLP 任务。
- 文本预处理
- 分词
- 停用词去除
- 词形还原
- 词干提取
- 词性标注
- 语言建模
- 词嵌入
- 新词发现
- 神经网络语言模型
- 文本分类
- 情感分析
- 主题分析
- 垃圾邮件检测
- 对话系统
- 机器翻译
- 统计机器翻译(SMT)
- 神经机器翻译(NMT)
- Transformer模型
- 命名实体识别
- 实体抽取
- 关系抽取
- 事件抽取
- 知识图谱构建
NLP Technology
针对以上任务,NLP 研究人员探索出了很多技术,不同技术对应于不同类型的任务。当我们遇到问题时,往往需要先将其对应到一个或多个任务,再在该任务的实现技术中选取一种适合我们使用的来执行任务。在自然语言处理 (NLP) 中用于从文本中提取数据的十大技术是:
Tokenization
在进行自然语言处理时,分词是最基本和最简单的 NLP 技术之一。在为任何 NLP 应用程序预处理文本时,分词是一个重要步骤。一个长时间运行的文本字符串被分解成更小的单元,称为标记,这些单元构成单词、符号、数字等。这些标记是构建块,有助于在开发 NLP 模型时理解上下文。大多数分词器使用“空格”作为分隔符来形成分词。基于建模的语言和目的,NLP 中使用了多种分词技术:
- 基于规则的分词
- 空白分词
- 空间分词器
- 子词分词
- 基于字典的分词
- Penn Tree的分词
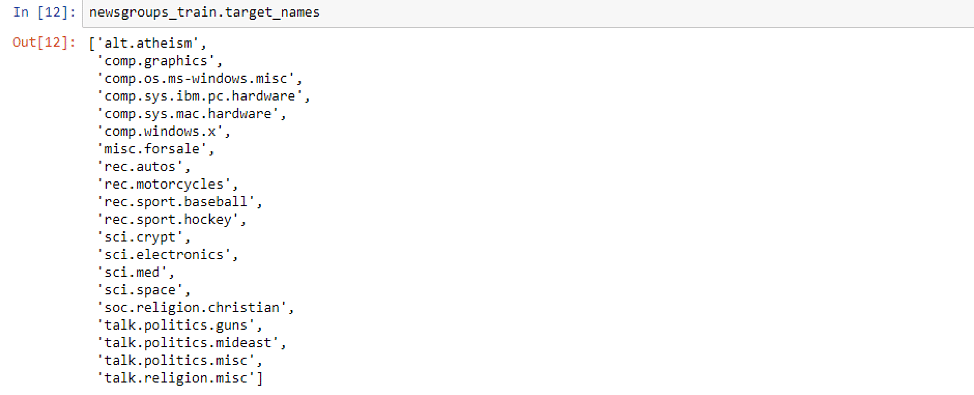
在 Python 中实现 Tokenization 技术,首先使用 scikit-learn 加载 20newsgroup 文本分类数据集。
from sklearn.datasets import fetch_20newsgroups
newsgroups_train = fetch_20newsgroups (subset= 'train')
该数据集包含 20 个不同类别的新闻。
该文本采用字符串形式,我们将使用 NLTK 的 word_tokenize 函数对文本进行分词,得到结果如下。
from nltk.tokenize import word_tokenize
tokenized=[]
for article in newsgroups_train.data:
tokenized.append(word_tokenize(article))

上面的输出不是很干净,因为它有单词、标点符号和符号。让我们编写一小段代码来清理字符串,同时删除换行符以及数字和符号,这样我们就只有单词了并将所有单词转换为小写。

import re
def clean_str(String):
String = re.sub(r"\\n", "", String) # to remove new-Line characters
String = re.sub(r"[^A-Za-z]", "", String)#to remove numbers, symbols
String = String-strip().lower)
return String
cleaned_text = []
for text in newsgroup_train.data:
cleaned_text.append(clean_str(text))
词干提取和词形还原
Tokenization之后的预处理流程中下一个最重要的 NLP 技术是词干化或词形还原。
例如,当我们在亚马逊上搜索产品时,假设我们不仅希望看到我们在搜索栏中输入的确切单词的产品,还希望看到我们输入的单词的其他可能形式的产品。如果我们在搜索框中输入“衬衫”,那么我们很可能希望看到包含“衬衫”形式的产品结果。在英语中,相似的单词根据其使用的时态及其在句子中的位置而出现不同的情况。例如,go、going、went 等单词都是相同的单词,但根据句子的上下文使用。
词干提取或词形还原 NLP 技术旨在从单词的这些变体生成词根。词干提取是一种粗略的启发式过程,它试图通过切断单词的结尾来实现上述目标,最终可能会或可能不会产生有意义的单词。
另一方面,词形还原是一种更复杂的技术,旨在通过使用词汇和词的形态分析来正确地做事。通过删除屈折词尾,它返回称为词条的单词的基本形式或字典形式。
让我们通过一个例子来理解词干提取和词形还原之间的区别。有许多不同类型的词干提取算法,我们将使用 NLTK 库中的 Porter Stemmer 后缀剥离算法,因为其效果最好。从以上结果可以看出,词干提取基本上是在最后砍掉字母以获得词根。
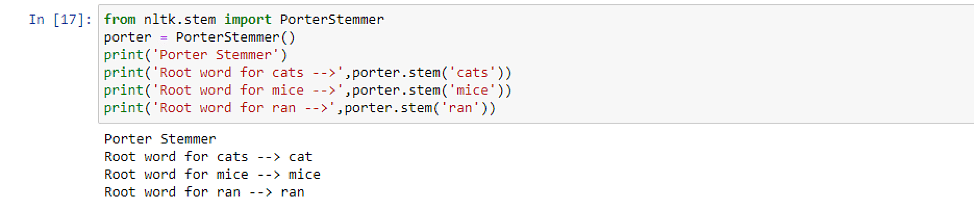
从以上结果可以看出,词干提取基本上是在最后砍掉字母以获得词根。然而,词形还原器成功地获取了“mice”和“ran”等单词的词根。考虑到这样一个事实,词干提取完全基于规则——我们在英语中有后缀来表示时态,比如“ed”、“ing”——比如“asked”和“asking”。它只是在单词末尾查找这些后缀并剪辑它们。这种方法并不合适,因为英语是一种歧义语言,因此词形还原器比词干分析器效果更好。

现在,在完成Tokenization之后,我们对 20newsgroup 数据集的文本进行词形还原,结果如下所示。
lemmatized = []
for text in tokenized:
c = []
for word in text:
doc = nlp(word)
for token in doc:
c.append(token.lemma_)
lemmatized.append (c)

停用词去除
词干化或词形还原之后的预处理步骤是停用词删除。在任何语言中,很多单词只是填充词,没有任何附加意义。这些主要是用来连接句子的词(连词——“because”、“and”、“since”)或用来表示一个词与其他词的关系(介词——“under”、“above”、in、in、 “在”) 。这些单词构成了人类语言的大部分,在开发 NLP 模型时并没有真正的用处。
然而,停用词移除并不是针对每个模型实施的明确 NLP 技术,因为它取决于任务。例如,在进行文本分类时,如果需要将文本分为不同的类别(类型分类、过滤垃圾邮件、自动标记生成)然后从文本中删除停用词会很有帮助,因为模型可以专注于定义数据集中文本含义的单词。对于类似的任务文本摘要和机器翻译,可能不需要删除停用词。
停用词去除有多种方法,可以使用 Genism、SpaCy 和 NLTK 等库来删除停用词。我们将使用SpaCy库来了解停用词删除 NLP 技术,SpaCy 提供了大多数语言的停用词列表。
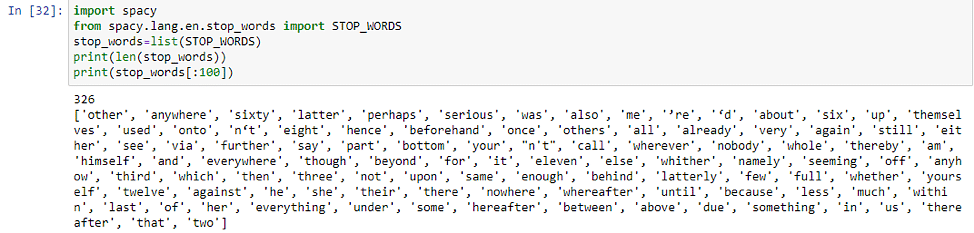
从词形还原文档中删除停用词只需几行代码。
stop_words_removed = []
for text in lemmatized:
c=[]
for word in text:
if word not in stop_words:
c. append (word)
stop_words_removed.append (c)
删除停用词至关重要,因为当我们在这些文本上训练模型时,由于这些单词的广泛存在,它们被赋予了不必要的权重,而实际上有用的单词则被降低了权重。
TF-IDF
TF-IDF 本质上是一种统计技术,用于说明单词对于文档集合中的文档的重要性。TF-IDF 统计度量是通过乘以 2 个不同的值(术语频率和逆文档频率)来计算的。
词频
词频用于计算单词在文档中出现的频率。它由此公式给出: \(TF(t,d) = \frac{d中t的计数}{d中单词的数量}\)
因此,通常出现在文档中的单词(例如停用词)——“the”、“is”、“will”将具有很高的术语频率。
逆向文档频率
在讨论逆文档频率之前,让我们首先了解文档频率。在多个文档的语料库中,文档频率衡量一个单词在整个文档语料库中的出现次数(N)。 \(DF(t) = t在N个文档中出现的次数\)
对于我们之前讨论过的常用英语单词来说,这个值会很高。逆文档频率与文档频率正好相反。 \(IDF(t) = \frac{N}{N个文档中t的出现次数}\)
这基本上衡量了我们语料库中术语的有用性。特定于特定文档的术语将具有较高的 IDF。生物医学、基因组等术语只会出现在与生物学相关的文档中,并且具有较高的 IDF。 \(TF-IDF = 词频*逆文档频率\)
TF-IDF 背后的整体思想是通过查找文档中出现频率较高但在语料库中其他位置不出现的单词来查找文档中的重要单词。对于与计算机科学相关的文档,这些词可能是计算、数据、处理器等;但对于天文文档,则可能是外星人、银河系、黑洞等。
现在,让我们了解 TF-IDF NLP 技术一个使用 Python 中的 Scikit-learn 库的示例。
from sklearn.feature_extraction.text import TfidfVectorizer
vectorizer = TfidfVectorizer()
X = vectorizer.fit_transform(newsgroups_train.data)
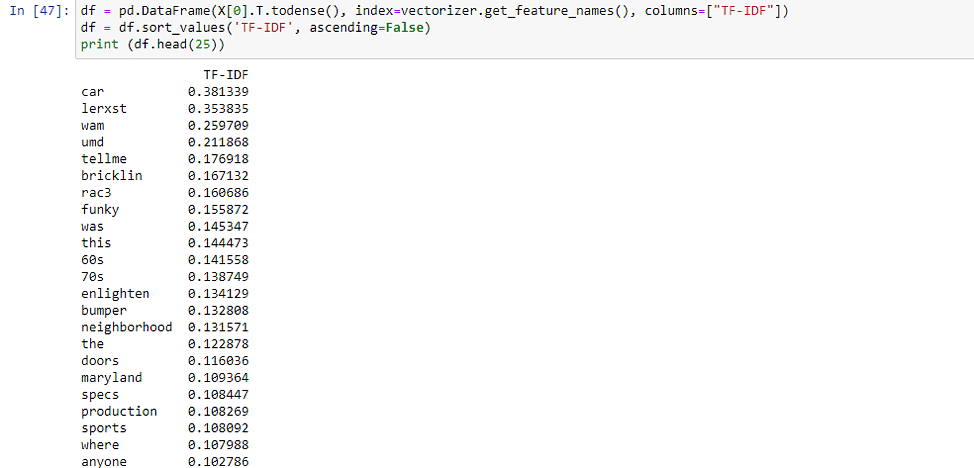
关键词提取
当你在手机、报纸或书本上阅读一段文字时,你会进行这种不自觉的浏览活动——你大多会忽略填充词,并从文本中找到重要的单词,而其他所有内容都符合上下文。关键字提取与在文档中查找重要关键字的作用完全相同。
关键词提取是一种文本分析NLP技术可在短时间内获得对某个主题有意义的见解。不必浏览文档,可以使用关键词提取技术来简洁文本并提取相关关键词。关键字提取技术在 NLP 应用程序中非常有用,在这种应用程序中,企业想要根据评论识别客户遇到的问题,或者如果您想要从最近的新闻项目中识别感兴趣的主题。
关键词的提取方式有很多种:
- 一种是通过我们上面看到的 TF-IDF。您可以提取 TF-IDF 最高的前 10 个单词,即为关键字
- 关键字提取的另一种方法是使用 Gensim,一个开源 Python 库
- 关键字提取也可以使用 SpaCy、YAKE(Yet Another Keyword Extractor)和 Rake-NLTK 来实现
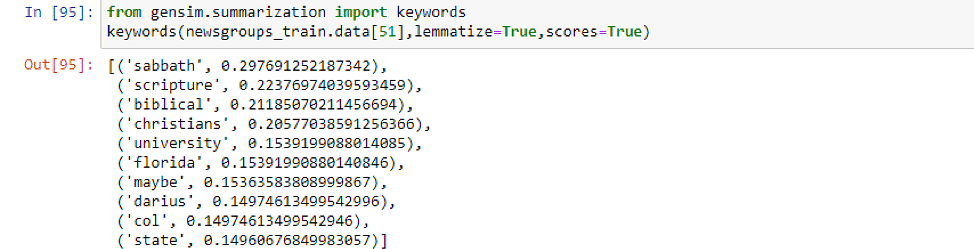
词嵌入
正如我们所知,机器学习和深度学习算法只接受数字输入,那么我们如何将一段文本转换为可以提供给这些模型的数字。在对文本数据训练任何类型的模型时,无论是分类还是回归,将其转换为数字表示是必要条件。答案很简单,遵循词嵌入方法来表示文本数据。这种 NLP 技术可以使具有相似含义的单词获得相似的表示。
词嵌入也称为向量,是语言中单词的数字表示。这些表示的学习使得具有相似含义的单词的向量彼此非常接近。单个单词被表示为实值向量或预定义的 n 维向量空间中的坐标。
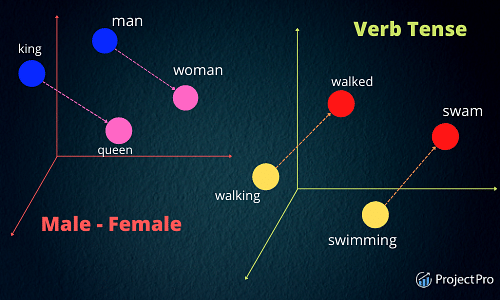
考虑如上在 3D 平面中表示的 3-3 维空间。每个单词都由该空间中的坐标(x,y,z)表示。在这个 3 维空间中,含义相似的单词会彼此接近。
- Walking 和 the king 之间的距离将大于 Walking 和 Walking 之间的距离,因为它们具有相同的词根 walk。
- 词嵌入对于理解词之间的关系也很有用——就像国王之于女王,男人之于女人。因此,在向量空间中,国王和王后之间的距离大约等于男人和女人之间的距离。
可以使用预定义的词嵌入(在维基百科等庞大的语料库上训练),也可以从头开始为自定义数据集学习词嵌入。有许多不同类型的词嵌入,如GloVe、WordVec、TF-IDF、CountVectorizer、BERT、ELMO 等。我们常用的是 Word2vec。
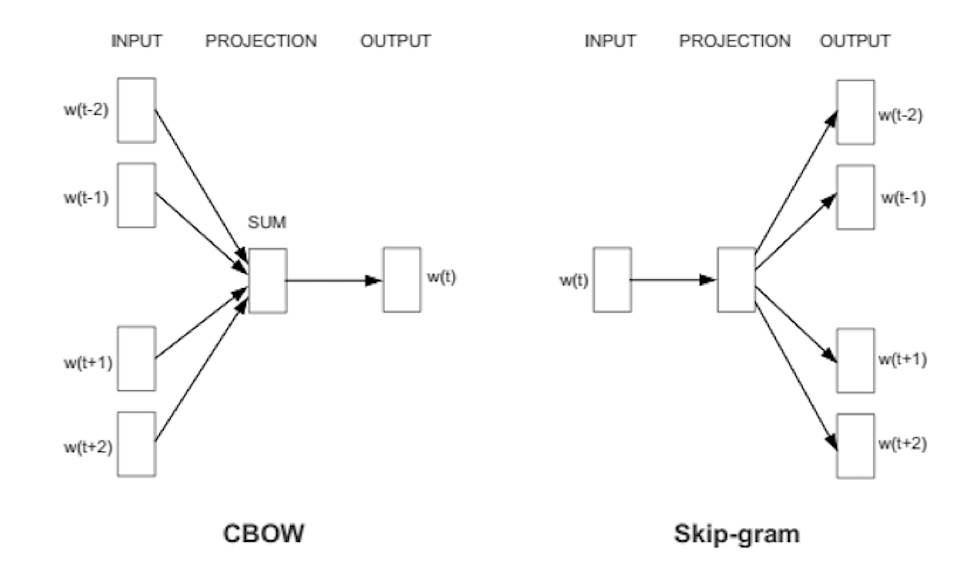
Word2Vec 是一种神经网络模型,可以从庞大的文本语料库中学习单词关联。Word2vec 可以通过两种方式进行训练,即使用通用词袋模型 (CBOW) 或 Skip Gram 模型。
在CBOW模型中,将每个单词的上下文作为输入,并预测与上下文对应的单词作为输出。考虑一个例句——“天气晴朗,阳光明媚”,在本句中,我们尝试预测的单词是 sunny,使用输入作为单词“The day is Bright”的 one-hot 编码向量的平均值。该输入经过神经网络后与目标词“sunny”的 one-hot 编码向量进行比较。计算损失,这就是 CBOW 中学习“sunny”这个词的上下文的方式。
Skip Gram 模型的工作原理与上述方法正好相反,我们将输入作为目标词“sunny”的单热编码向量发送,并尝试输出目标词的上下文。对于每个上下文向量,我们得到 V 概率的概率分布,其中 V 是词汇大小,也是上述技术中单热编码向量的大小。
在 python 中实现 Word2vec 的步骤如下:第一步是下载谷歌预定义的Word2Vec文件;下一步是将 GoogleNews-vectors-negative300.bin 文件放在当前目录中,可以使用 Gensim 加载此向量。
from gensim.models import keyedvectors as word2vec
model = word2vec.KeyedVectors.load_word2vec_format('GoogleNews-vectors-negative300.bin', binary=True)
这个嵌入有 300 个维度,即对于词汇表中的每个单词,我们都有一个 300 个实数值的数组来表示它。现在,我们将使用 word2vec 和来计算诸如 king、queen、walked 等词之间的距离。
from sklearn.metrics.pairwise import cosine_similarity
d1=cosine_similarity(model['king'].reshape(1,-1), model['queen'].reshape (1, -1))[0][0]
d2=cosine_similarity(model['king'].reshape(1,-1), model['walked'].reshape (1, -1)) [0][0]
print('The distance between king and queen is', d1, 'and the distance between king and walked is' ,d2)
情感分析
情感分析也称为情感 AI 或观点挖掘,是文本分类最重要的 NLP 技术之一。目标是将推文、新闻文章、电影评论或网络上的任何文本等文本分类为这 3 个类别之一:正面/负面/中立。情绪分析最常用于减少社交媒体平台上的仇恨言论,并从负面评论中识别出陷入困境的客户。
我们需要处理三个类别:0 是中性的,-1 是负面的,1 是正面的。在数据是清理干净后,我们仍然需要之前讲到的 NLP 技术,例如分词、词形还原和停用词删除等来进行数据预处理,具体过程如下:
到目前为止,我们还没有做过任何新的事情。我们在文章开头讨论的预处理步骤相同,然后使用 word2vec 将单词转换为向量。现在,我们将数据分为训练数据集和测试数据集,并在训练数据集上拟合逻辑回归模型。

逻辑回归是用于分类问题的线性模型。在转向复杂模型之前,最好先拟合一个简单模型。让我们看看我们在测试集上的表现。

考虑到我们使用逻辑回归等简单模型的默认设置,65% 的准确度已经不错了。在此基础上还可以进行很多实验来提高机器学习模型的性能:
- 试验逻辑回归中的超参数。
- 使用稍微复杂一点的模型,例如朴素贝叶斯或 SVM。
- 将文本转换为向量后,使用 MinMax Scaler 等标准化技术。
主题建模
主题建模是一种统计 NLP 技术,可分析文本文档语料库以查找隐藏在其中的主题。最好的部分是,主题建模是一种无监督机器学习算法,这意味着它不需要对这些文档进行标记。这项技术使我们能够以人工注释无法达到的规模来组织和总结电子档案。潜在狄利克雷分配是用于主题建模的最强大的技术之一。基本直觉是每个文档都有多个主题,每个主题分布在固定的词汇表上。让我们通过一个例子来理解这一点。
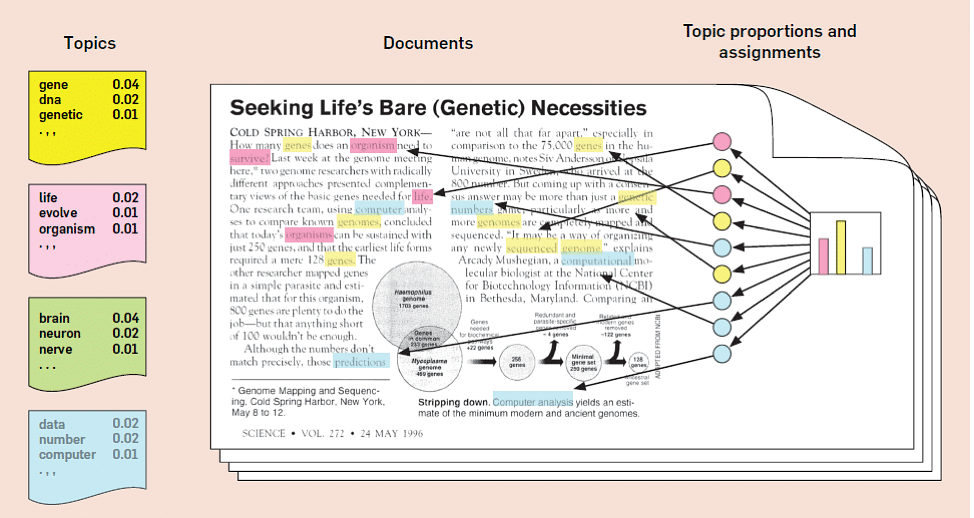
为了进行主题模型建模,我们和之前一样也需要预处理步骤——分词、词形还原和停用词删除。

Corpora.dictionary 负责创建单词与其整数 ID 之间的映射,与字典中的非常相似。现在,让我们对此拟合一个 LDA 模型,并将主题数量设置为 3。

此外还可以使用 pyLDAvis 可视化LDA模型的输出结果。
import pyLDAvis
import pyLDAvis.gensim
pyLDAvis.enable_notebook()
vis = pyLDAvis. gensim.prepare(lda_model, corpus, dictionary)
vis
如图所示,每个圆圈代表一个主题,每个主题分布在右侧所示的单词上。
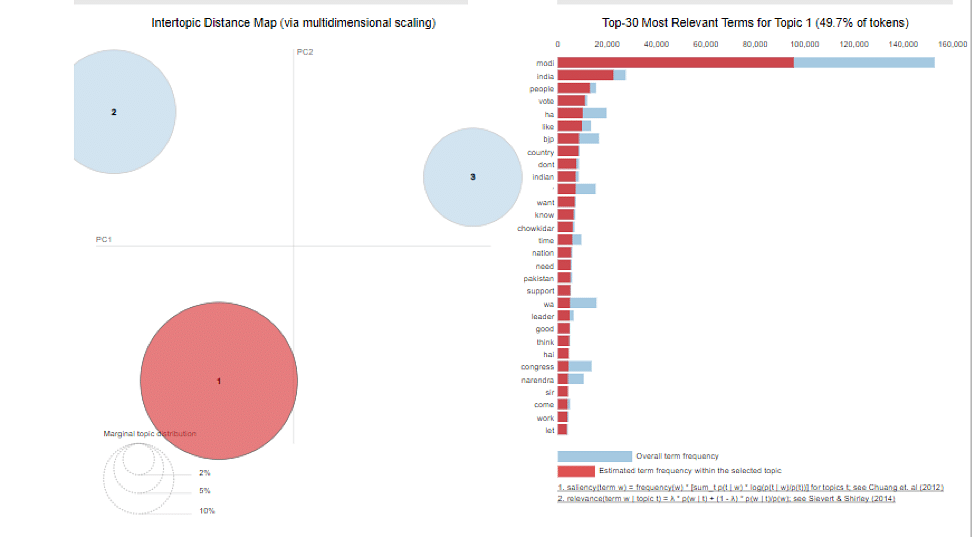
pyLDAvis 提供了一种非常直观的方式来查看和解释拟合的 LDA 主题模型的结果。选择主题数量的最佳方式取决于两个因素:
- 主题应该有不同的可分离主题。一个主题不应包含两个容易分离的主题。在这种情况下,可以增加主题数量并查看。
- 主题之间不应有重叠。不同的话题应该有尽可能不同的主题。重叠也可以通过上图中重叠的圆圈看出。
文本摘要
这种 NLP 技术用于以流畅、连贯的方式简洁、简短地总结文本。摘要对于从文档中提取有用信息非常有用,而无需逐字阅读。如果由人来完成,这个过程非常耗时,自动文本摘要从根本上减少了时间。
目前有两种类型的文本摘要技术:
- 基于提取的摘要:在这种技术中,提取文档中的一些关键短语和单词来进行摘要。对原文没有做任何改动。
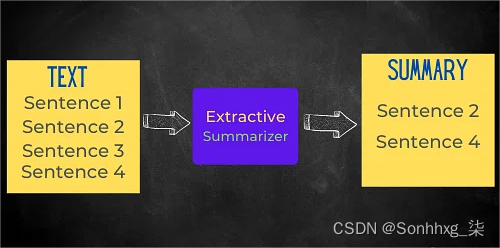
- 基于抽象的摘要:在这种文本摘要技术中,从捕获最有用信息的原始文档中创建新的短语和句子。摘要的语言和句子结构与原始文档不同,因为这种技术涉及释义。我们还可以克服基于提取的方法中发现的语法不一致。

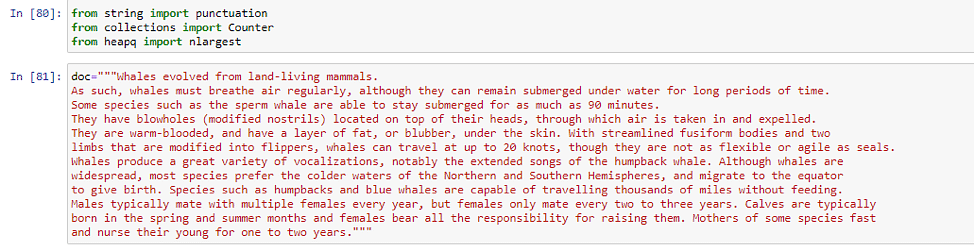
我们将使用 Spacy 在 python 中实现文本摘要。我们还定义了要总结的文档。
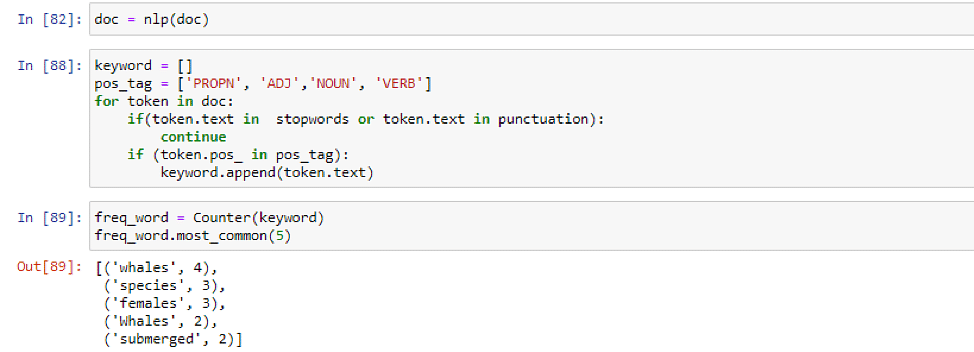
下一步是对文档进行标记并删除停用词和标点符号。之后,我们将使用计数器来计算单词的频率并获取文档中出现频率最高的 5 个单词。
完成以上操作后,我们通过除以最大频率来标准化频率,以便更好地处理数据。

现在,我们将根据单词在句子中出现的频率(使用上述标准化频率)来衡量句子的权重。

最后一步是使用 nlargest 获取文档中权重最高的 3 个句子来生成摘要。

命名实体识别
NER是信息提取的一个子领域,它处理从非结构化文档中定位命名实体并将其分类为预定义的类别,如人名、组织、位置、事件、日期等。NER 在某种程度上类似于关键字提取,只不过提取的关键字被放入已经定义的类别中。Spacy 中有内置函数可以执行此操作。
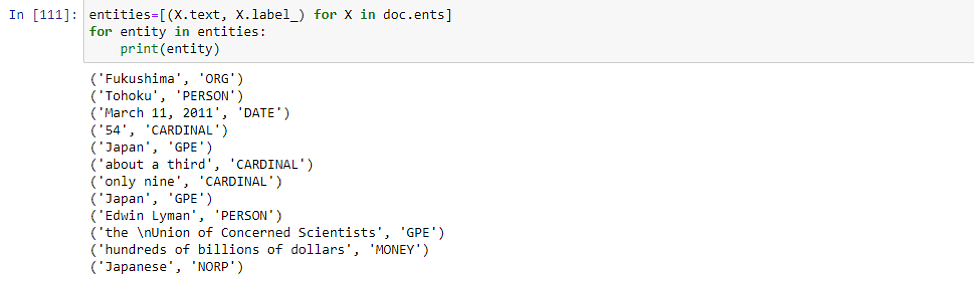
此外还可以使用 SpaCy 提供的函数 displacy 来可视化带有实体的文本。
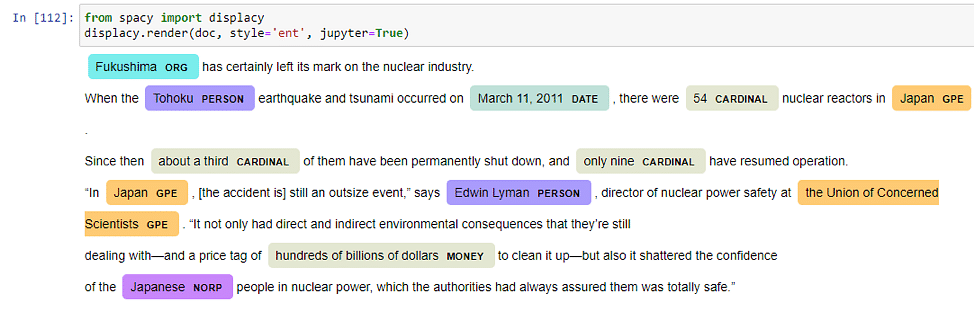
我们使用的是预定义的 NER 模型,当然也可以从头开始训练自己的 NER 模型,当数据集非常特定于域并且 SpaCy 无法在其中找到大多数实体时,这很有用。例如对于印度城市和公众人物的名字的提取——spacy 无法准确地标记它们。
Summary
- 文本预处理领域的部分 NLP 技术,例如分词、词形还原、停用词删除,不管你正在处理的是什么 NLP 任务,其均要被使用。
- 其他NLP技术在分析文本时更有用,例如 TF-IDF、关键字提取、文本摘要和 NER。它们还可以作为在分类任务上训练 NLP 模型时的骨干,因为它们可以轻松地从文本中提取有用的信息。
- 主题建模、命名实体识别等 NLP 技术在从大型语料库中提取主题和标记数据集方面非常有用
This is italic. This is Bold. * If asterisk is surrounded by spaces, it is not parsed. *
This is also italic. This is also Bold. _ If underscore is surrounded by spaces, it is not parsed. _
This is strike through.
There is no underline in markdown. You can use html tags like this to underline.
This is a code block.
This is an external link. “https://” is important. This is an internal link. Internal links are all lowercase with space replaced by hyphens “-“.
You can mix them like this, this, this, but not like [this](https://bit.ly).
Comments
Be the first one to comment on this page!